|
He is a researcher in artificial intelligence and mathematics. he is working on reasoning, AI safety and Multimodal. He always supports Slow ScienceEmail: echo T3pULkpAaWNsb3VkLmNvbQ== | base64 -d If you would like to join his group in any other capacity, please fill this form and then please send him a short email note without any documents. |

|
|
|
|
|
VRHF: RLVR from Human Feedback Oz T. Jang [paper] (Writing) Propose combining RLHF with RLVR Large Reasoning Model 2025 |
|
|
Double Zero: Self-Evolving Reasoning with Zero Data, Zero RL Oz T. Jang [paper] (Writing) Propose Double Zero Self-Evolving Large Reasoning Models without data, without SFT 2025 |
|
|
SFT-hybrid-RFT Large Reasoning Model Oz T. Jang [paper] (Writing) Propose SFT-hybrid-RFT Large Reasoning Model 2025 |
|
|
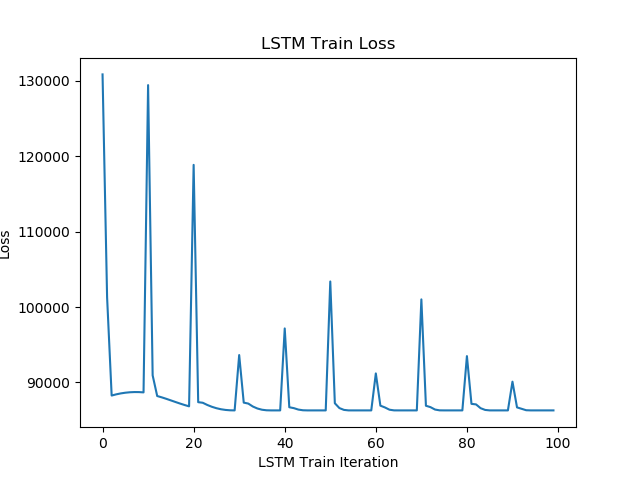
Lookahead-LSTM BiO: Lookahead-LSTM Bilevel Optimization for Large Reasoning Model Chaoyue Yang,Ruijie Xie,Oz T. Jang [paper] (Writing) Propose Lookahead-LSTM Bilevel Optimization for Large Reasoning Models 2025 |
|
Lookahead-LSTM Optimizer: A Meta-Learning K-steps Method Oz T. Jang, Teng Yang, Xiaozhu Hu, Zi Yang, Chifong Wong [paper] (Under Review ICLR 2026) [code] Propose a Meta-learning optimization method named Lookahead-LSTM for improving generalization and data transferability. 2020 Spring |
|
|
|
|
Multi-view Learning for Vision-and-Language Planning Oz T. Jang, Wei Yuan Generating multi-view videos as a world state representation,combining VLMs with text-to-video models to obtain the ability of long-horizon decision making 2023 Winter |

|
Multimodal Perception Fusion for Robotic Manipulation Oz T. Jang, Zhigang Li , Bowen Fu Merge object 6-DoF information and improve the performance of object localization for robotic manipulation 2019 Fall |
|
Starting January 2025, I have decided to commit 1~2 hours every week to provide guidance, suggestions, and/or mentorships for students from underrepresented groups or whoever is in need. Please fill in this form if you are interested. |
This template is a modification to Jon Barron's website template |